Best practices To Build A Data Lake
The need for big data is inevitable. Data is the new currency and it is estimated that 90% of the data in the world today has been created in the last two years alone, with 2.5 quintillion bytes of data created every day. With this amount of data being created, companies are facing greater challenges to ensure that they are using their data in the best way possible, and creating a data lake is one such method.
A data lake is a vast pool of raw data that comprises structured and unstructured data. This data can be processed and analyzed later on. Data lakes eliminates the need for implementing traditional database architectures.
This blog post will discuss the best practices to build a data lake. So, without further ado, let’s get started.
Benefits of Data Lake
To combat the issue of 360-degree visibility of your organization’s data which includes customer’s behavioral patterns and other sensitive data. By creating a data lake that too a centralized one, it becomes easier to access data at the time of crisis or to quicky resolve any customer issue. This also helps in taking timely decisions thus saving organizations from any inefficient planning and business risks.
- No more hassle
With centralized data being available easily, the struggle of searching required data gets changed into a streamlined mode of searching. It's like creating a master folder in your cloud and labelling all the important sub folders in a way that any data related to them is easily accessible.
This is further helpful in not having any sort of data duplication, applying multiple security policies with data properly consolidated and cataloged at one place.
- Format won't be an issue
With data lake you have the freedom to store data in any format that you are comfortable with as it eliminates the need of data modelling. So, whether your data is in RDBMS, NoSQL or any other format, it will never be an issue. Data lake is low in cost in comparison to other traditional data warehouses which acts as an added advantage.
- Improved data value
As there are no predefine schemas for data processing, data lake is the best option to store raw data. It processes this data even without any clue of the type of analysis that might be needed in the future. This way it kind of empowers your organization by maximizing your data’s value and security with the help of cloud-based solutions.
- Easy data analysis
Having a centralized repository in the form of data lakes, it gives multiple sets of data that can be combined for various machine learning models. This gives added benefits for predictive analysis for various Machine Learning and Artificial Intelligence based analytical services.
Best Practices To Build A Data Lake
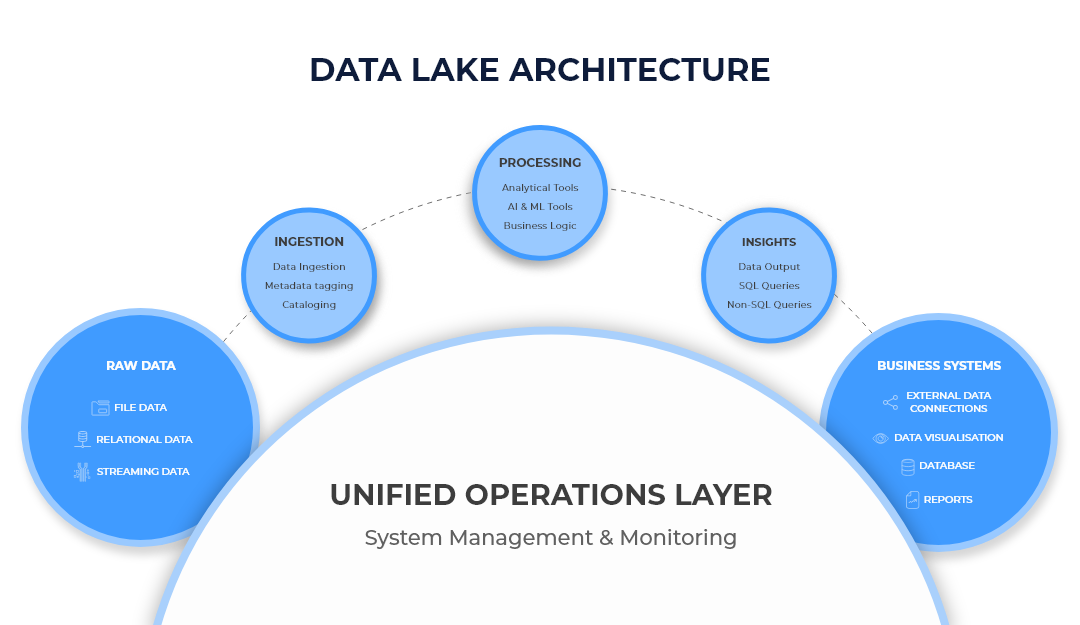
- Regulation Of Data Ingestion: Data ingestion is the flow of data from its origin to data stores such as data lakes, databases, and search engines. As we add new data to the data lake, it is important to preserve the data in its native form. By doing so, we can generate outputs of analysis and predictions with greater accuracy. This includes preserving even the null values of the data, out of which proficient data scientists squeeze out analytical values when needed.
When To Perform Data Aggregation?
Aggregation can be carried out when there is PII(Personally Identifiable Information) present in the data source. The PII can be replaced with a unique ID before the sources are saved to the data lake. This bridges the gap between protecting user privacy and the availability of data for analytical purposes. It also ensures compliance with data regulations like GDPR, CCPA, HIPAA, etc.
- Designing The Right Data Transformation Idea: The main purpose of collecting data in data lake is to perform operations like inspection, exploration, and analysis. If the data is not transformed and catalogued correctly, it increases the workload on the analytical engines. The analytical engines scan the entire data set across multiple files, which often results in query overheads.
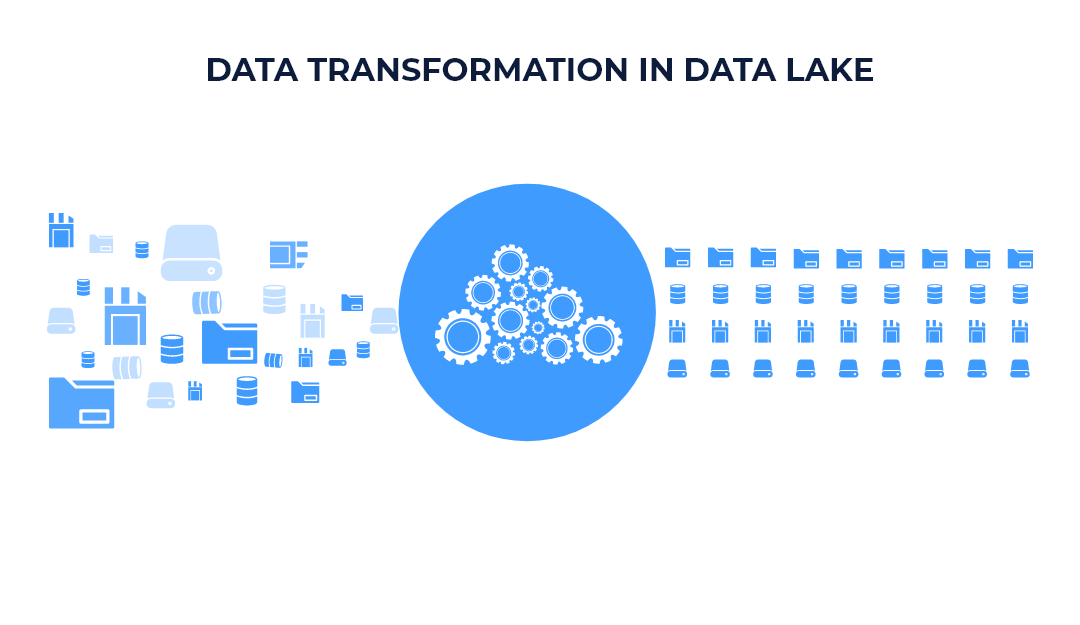
How To Design The Right Data Transformation Strategy?
- Store the data in a columnar format such as Apache Parquet or ORC, these formats offer optimized reads and are open-source, which increases the availability of data for various analytical services.
- Partitioning the data concerning the time stamp can have a great impact on search performance.
- Small files can be chunked into bigger ones asynchronously. This helps in reducing network overheads.
- Using Z-order indexed materialized views would help to serve queries including data stored in multiple columns.
- Collect data set statistics like file size, rows, and histogram of values to optimize queries with join reordering.
- Collect column and table statistics to estimate predicate selectivity and cost of plans. It also helps to perform certain advanced rewrites in the data lake.
- Prioritising Security In A Data Lake: The RSA Data Privacy and Security survey conducted in 2019 revealed that 64% of its US respondents and 72% of its UK respondents blamed the company and not the hacker for the loss of personal data. This is due to the lack of fine-grained access control mechanisms in the data lake. Along with the increase in data, tools, and users, there is a dynamic increase in the risks of security breaches. Hence, curating a security strategy even before building a data lake is important. This would grab the attention of the increased agility that comes with the use of a data lake. The data lake security protocols must account for compliance with major security policies.
Key Points For Curating An Efficient Security Strategy
- Authentication and authorization of the users who access the data lake must be enforced. For instance, person A might have access to edit the data lake whereas person B might have permission only to view it. They must be authenticated using passwords, usernames, multiple device authentication, etc. Integrating a strong ID management tool in the underlying cloud service provider would help in achieving this.
- The data should be encrypted at all levels i.e. when in transit and also at rest so that only the intended users can understand and use it.
- Access should be granted only to skilled and well-experienced administrators, thus minimizing the risk of breaches.
- The data lake platform must be hardened so that its functions are isolated from the other existing cloud services.
- Host security methods such as host intrusion detection, file integrity monitoring, and log management should be enhanced.
- Redundant copies of critical data must be stored as a backup option in another data lake so that it comes in handy in cases of data corruption or accidental deletion.
- Implementing Well-Formulated Data Governance Strategies: A good data governance strategy ensures data quality and consistency. It prevents the data lake from becoming an unmanageable data swamp.
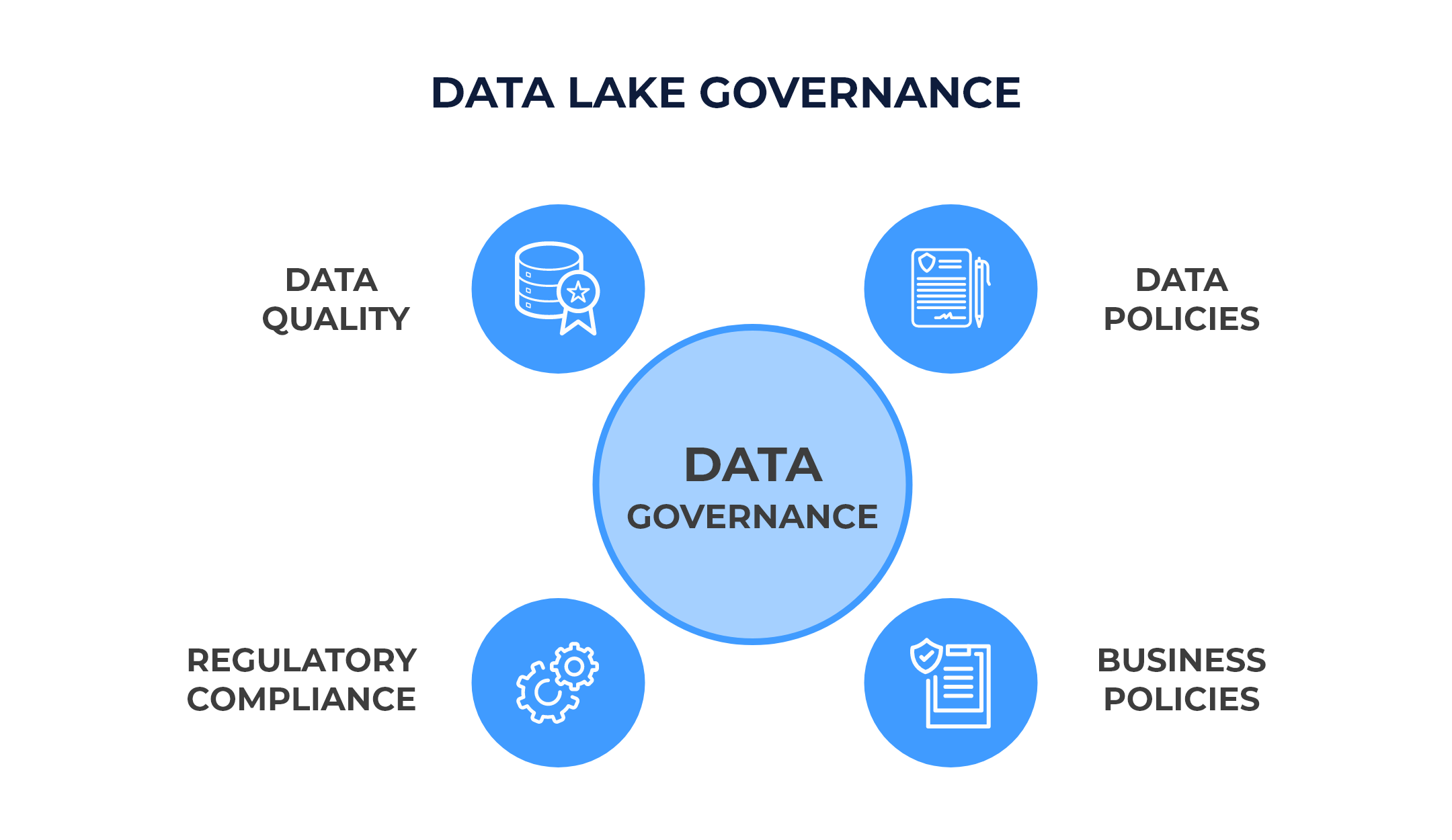
Key Points For Crafting A Data Lake Governance Strategy
- Data should be identified and catalogued. The sensitive data must be clearly labelled. This would help the users achieve better search results.
- Creating metadata acts as a tagging system to organize data and assist people during their search for different types of data without confusion.
- No data should be stored beyond the time specified in the compliance protocols. This would result in cost issues along with compliance protocol violations. So, defining proper retention policies for the data is necessary.
Conclusion
One thing is clear from this blog that data lake is of utmost importance as it gives the whole organization complete access to the data. For any team whether a development team, DevOps team, etc., it becomes easier to get solutions for the issues that arise due to lack of data. It is also one of the best ways to respond to customers’ queries and tickets raised related to your product or services.


